TLDR
- We show that memorization is typically not localized to specific model layers, rather is confined to a small fraction of neurons dispersed across the model.
- We propose Example-Tied Dropout that can confine memorization to a pre-defined set of neurons, which can then be thrown away at test time.
#1: Is Memorization Localized to Final Layers?
Past works have suggested that memorization is typically confined to the final few model layers:
“early layers generalize while later layers memorize”
“memorization predominantly occurs in deeper layers”
"generalization can be restored by reverting the final few layer weights”
Our work challenges this belief with three different probes revealing that memorization is dispersed across model layers.
Gradient Accounting
- Setup: Track the norm of the aggregate gradient of mislabeled & clean examples per layer during training of the model. Average across all epochs.
- Observation:
- Even though noisy examples account for only 10% of the dataset, they have a comparable gradient norm to clean ones (90%)
- Gradients of clean & noisy examples have extremely -ve cosine similarity throughout training.
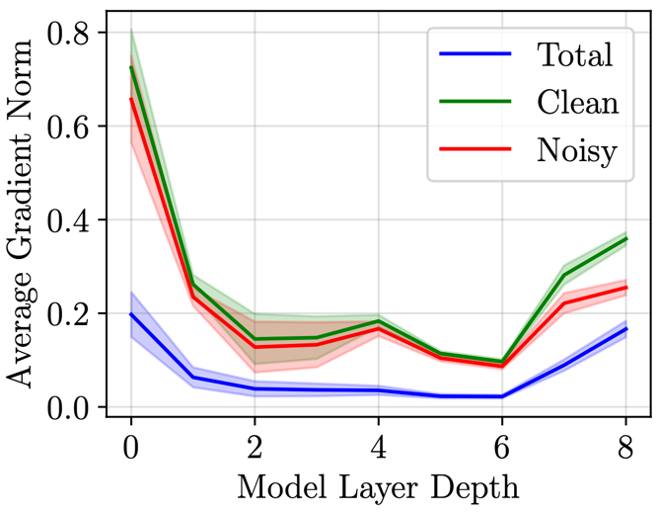
Gradient norm contribution from noisy examples closely follows that for clean examples even when they constitute only 10% of the dataset. Results depicted for epochs 15-20 for ResNet-9 trained on CIFAR-10 with 10% label noise.
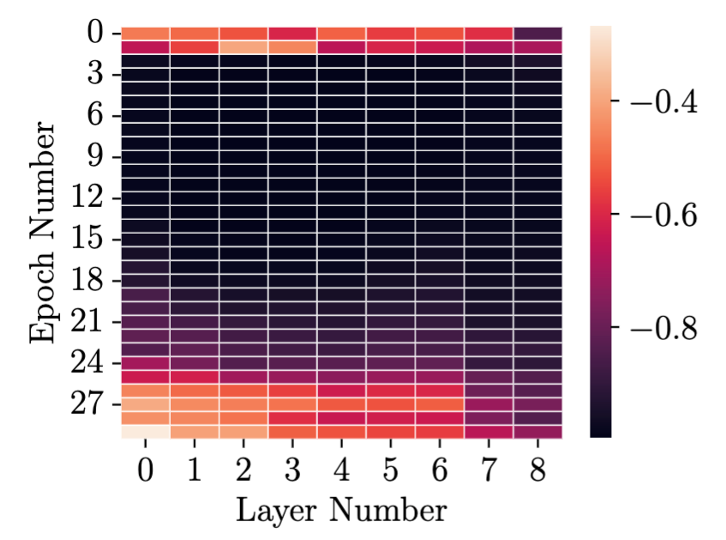
Cosine similarity between the average gradients of clean and mislabeled examples per layer, per epoch for ResNet9 on CIFAR10 with 10% label noise. The memorization of mislabeled examples happens between epochs 10–30
Layer Rewinding
- Setup:
- Checkpoint model after every epoch during training
- Rewind individual layer weights to an earlier epoch; leave remaining model frozen
- Measure accuracy on clean & noisy training points.
- Observation:
- Rewinding the last layers to an epoch before the noisy examples were learnt (as per the training curve) does not impact the accuracy on them significantly. This suggests that the last layers are typically not critical to the memorization of mislabeled examples.
- Critical layers change with the complexity of the dataset & architecture. (see full results on other architectures and datasets in the paper)
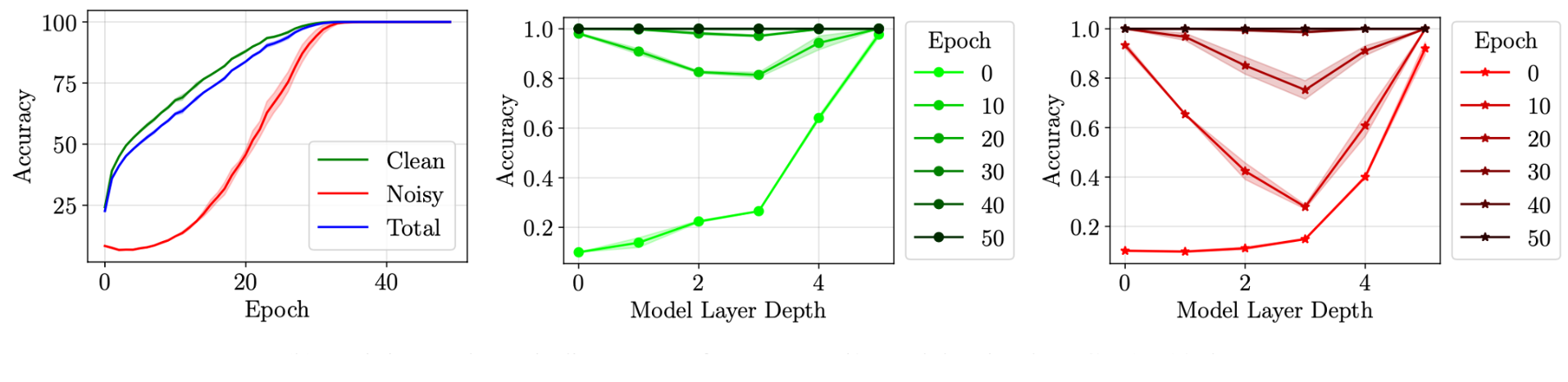
Change in model accuracy on rewinding individual layers to a previous training epoch for clean examples (left) and mislabeled examples (right). The dataset has 10% random label noise. Epoch 0 represents the model weights at initialization.
Layer Retraining
- Setup:
- Checkpoint model initialization; train to convergence
- Rewind model weights of individual layers to initialization, keeping rest of the model frozen.
- Now train the rewound layer on only clean samples.
- Track accuracy on clean & noisy points while training.
- Observation: Training on only clean examples confers large accuracy on noisy examples. This confirms that the information required to predict correctly on noisy examples is already contained in other model layers.
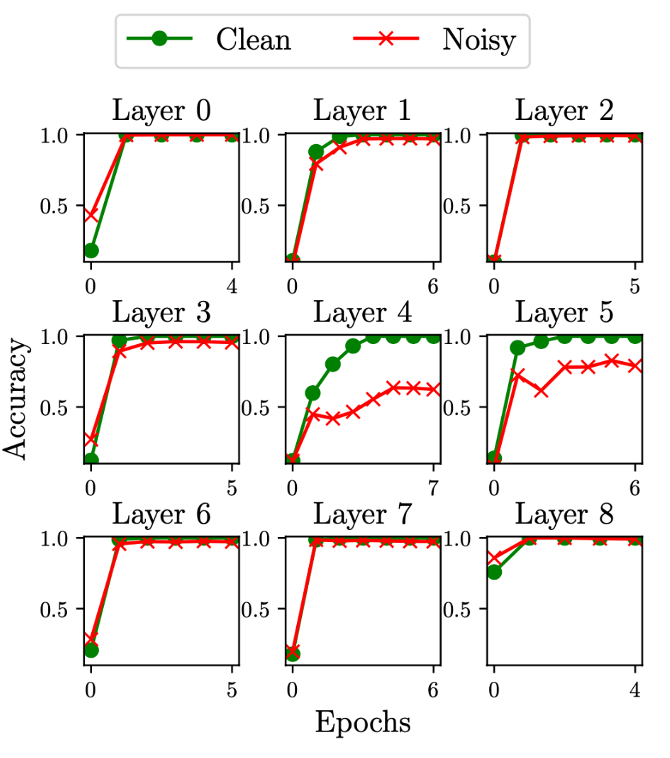
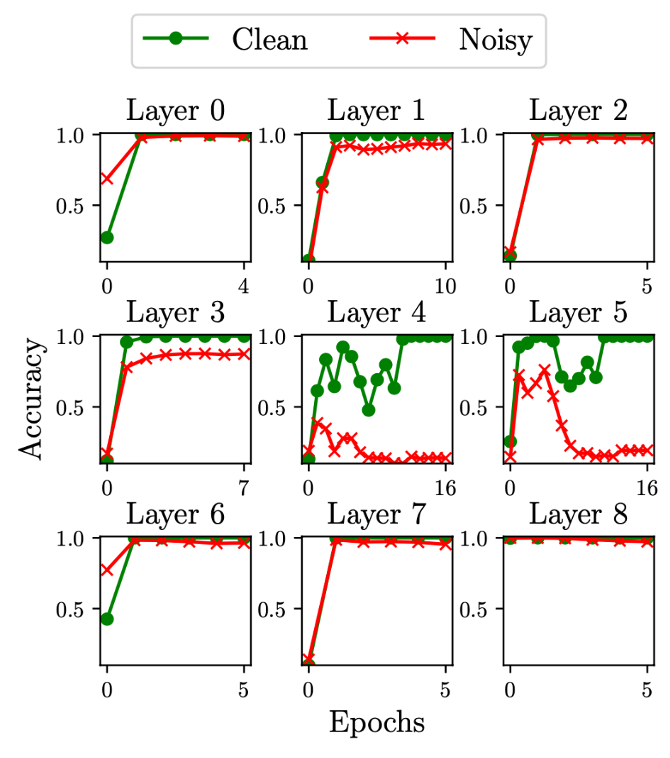
Layer retraining for CIFAR-10 (left) and MNIST (right). We see that layers 4 and 5 are more important for memorization because all other layers can be trained to 100% accuracy on memorized examples, when only trained on clean examples.
#2: Localizing Memorization to Fixed Neurons
Greedy Neuron Removal from a Converged Model
- Setup:
- For a given training example, find the neuron in the model that maximizes the loss on that example if removed but does not increase the average loss on the remaining training samples significantly.
- Zero-out activations from that neuron. Repeat this process until the prediction is flipped.
- Observation:
- Memorized examples need fewer neurons to flip the prediction.
- Upon flipping their prediction, the drop in training set accuracy is much lower.
- Critical neurons are distributed across layers for both typical & memorized samples.
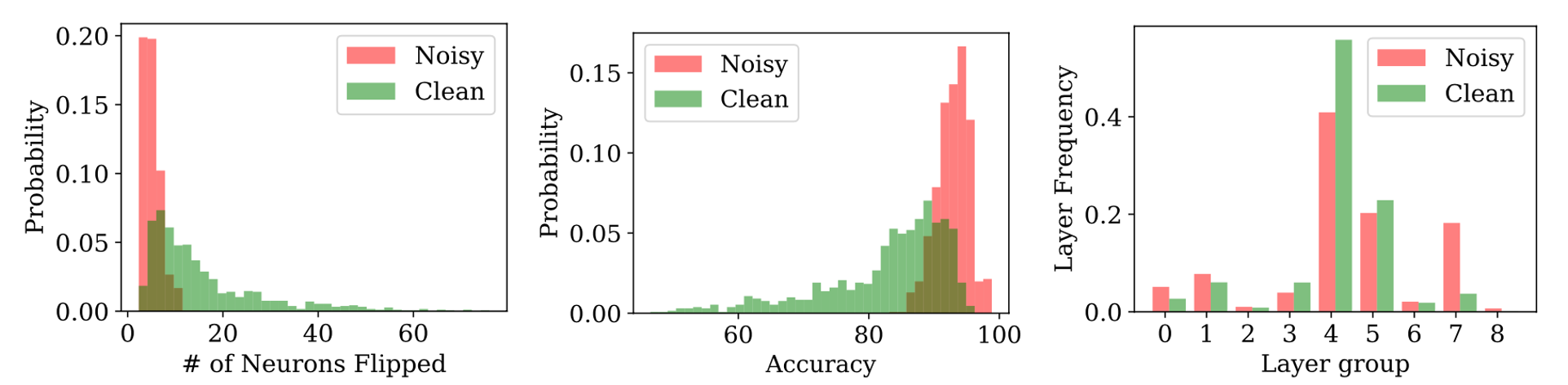
For each example in a subset of 1000 clean and 1000 noisy examples, we iteratively remove the most important neurons from a ResNet-9 model trained on the CIFAR-10 dataset with 10% random label noise, until the example’s prediction flips.
Method: Example-Tied Dropout
- Generalization Neurons: A fraction of neurons that always fire and are responsible for generalization.
- Memorization Neurons: Neurons that only fire for its corresponding (training) example.
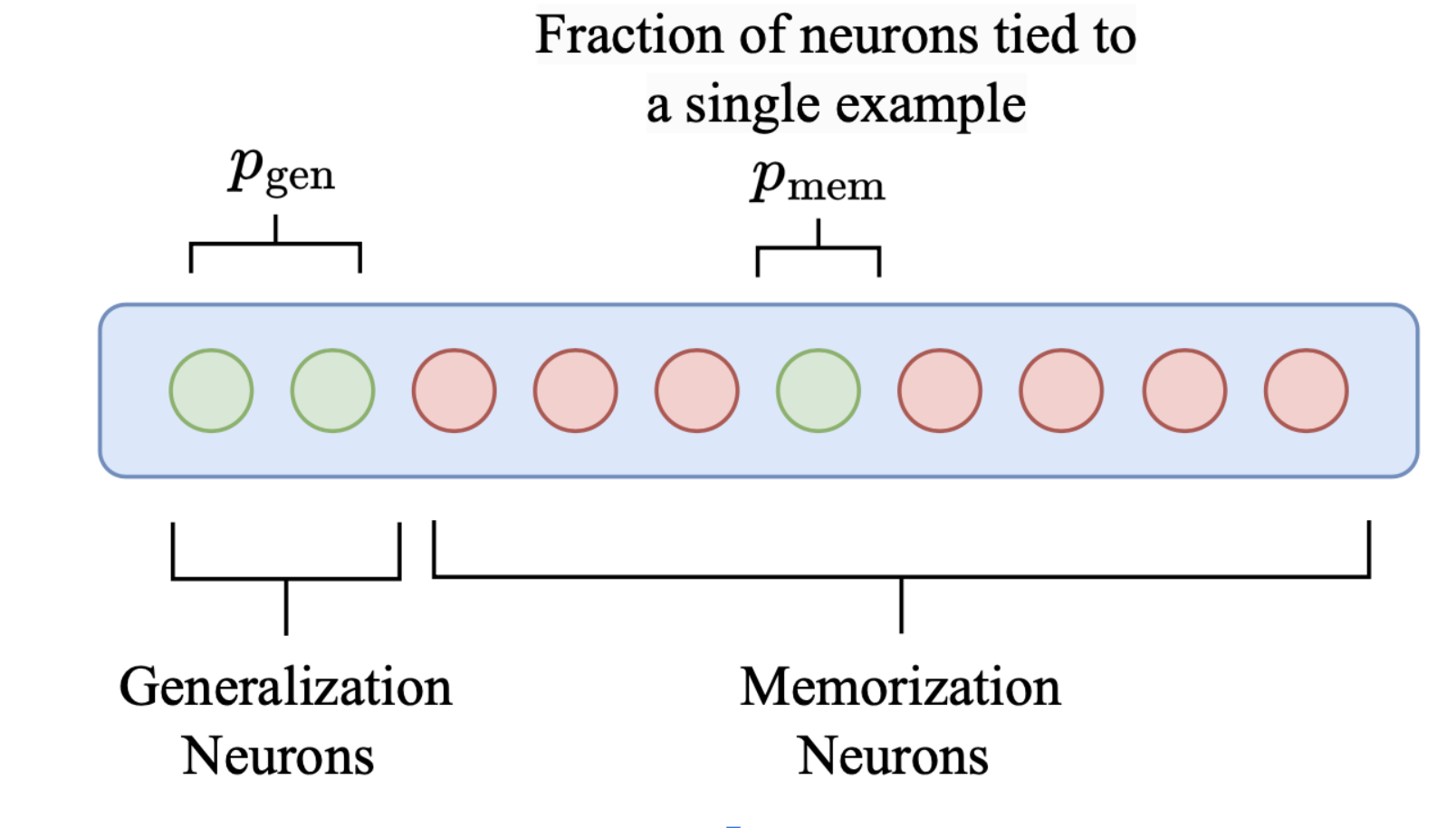
A schematic diagram explaining the difference between the generalization and memorization neurons. At test time, we dropout all the memorization neurons.
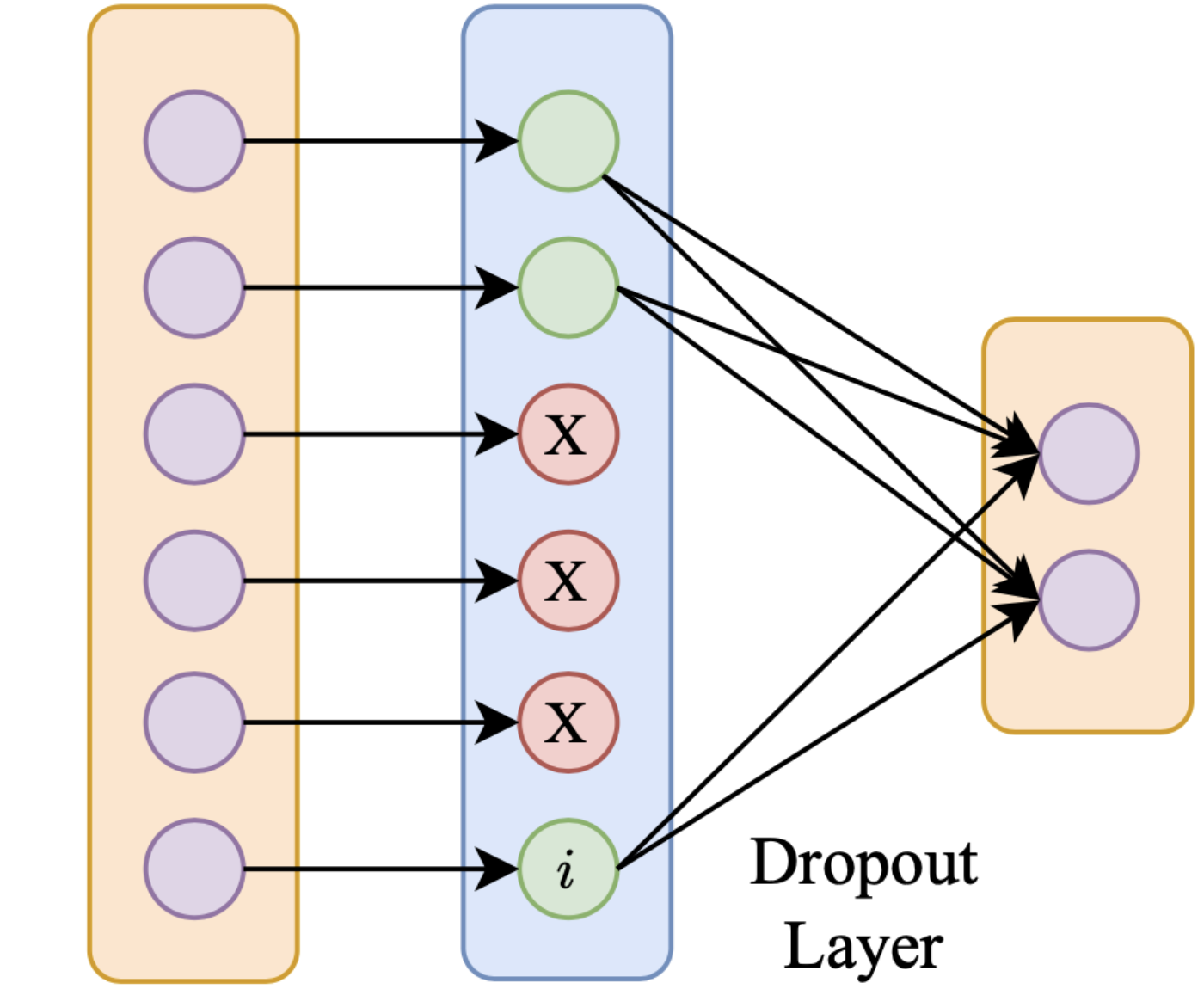
Forward propagation for input tied to the ith memorization neuron. The neuron is activated only when the corresponding input is in the training batch.
Results
Example-Tied Dropout is a simple and effective method to localize memorization in a model.
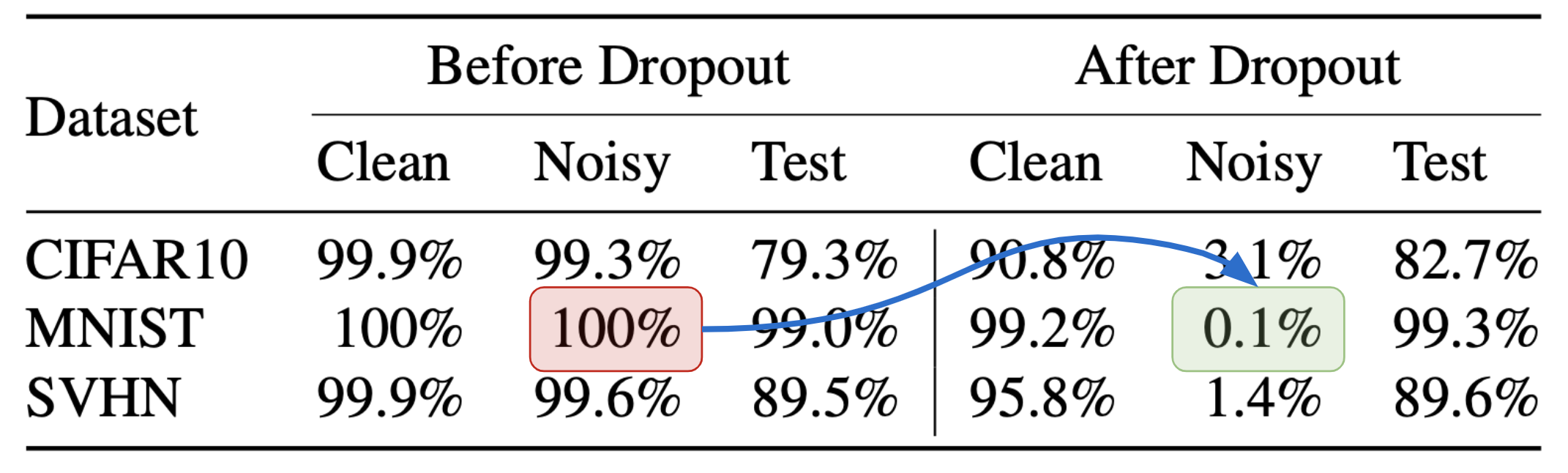
Dropping out memorization neurons leads to a sharp drop in accuracy on mislabeled examples with a minor impact on prediction on clean and unseen examples.

Most of the clean examples that are forgotten when dropping out the neurons responsible for memorization in the case of Exampletied dropout were either mislabeled or inherently ambiguous and unique requiring memorization for correct classification.